解释器模式
目的
为语言创建解释器,通常由语言的语法和语法分析来定义。
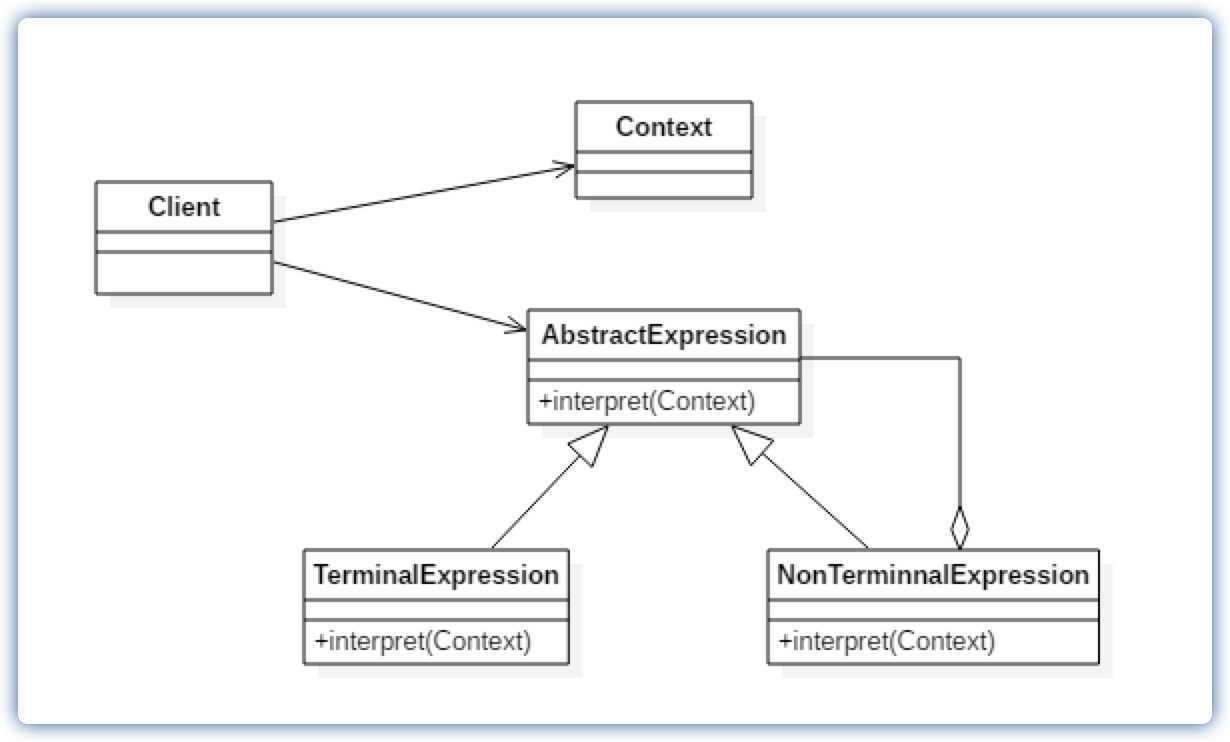
类图
角色
AbstractExpression抽象解释器:声明一个所有具体表达式都要实现的抽象接口(或者抽象类),接口中主要是一个interpret()方法,称为解释操作。TerminalExpression终结符表达式:实现与文法中的元素相关联的解释操作,通常一个解释器模式中只有一个终结符表达式,但有多个实例,对应不同的终结符。终结符一半是文法中的运算单元,比如公式R=R1+R2,R1和R2就是终结符,对应的解析R1和R2的解释器就是终结符表达式。NonTerminalExpression非终结符表达式:文法中的每条规则对应于一个非终结符表达式,非终结符表达式一般是文法中的运算符或者其他关键字.比如公式R=R1+R2,+就是非终结符,解析+的解释器就是一个非终结符表达式。非终结符表达式根据逻辑的复杂程度而增加,原则上每个文法规则都对应一个非终结符表达式。Context环境角色:一般是用来存放文法中各个终结符所对应的具体值,比如R=R1+R2,给R1赋值100,给R2赋值200。这些信息需要存放到环境角色中,大多使用Map来充当环境角色。
实现
实现规则检验器,具有 and 和 or 规则,可以构建一颗解析树,用来检验一个文本是否满足解析树定义的规则。
例如一颗解析树为 D And (A Or (B C)),文本 "D A" 满足该解析树定义的规则。
这里的 Context 指的是 String。
抽象解释器
public abstract class Expression {
public abstract boolean interpret(String str);
}终结符表达式
public class TerminalExpression extends Expression {
private String literal = null;
public TerminalExpression(String str) {
literal = str;
}
public boolean interpret(String str) {
StringTokenizer st = new StringTokenizer(str);
while (st.hasMoreTokens()) {
String test = st.nextToken();
if (test.equals(literal)) {
return true;
}
}
return false;
}
}
非终结符表达式
public class AndExpression extends Expression {
private Expression expression1 = null;
private Expression expression2 = null;
public AndExpression(Expression expression1, Expression expression2) {
this.expression1 = expression1;
this.expression2 = expression2;
}
public boolean interpret(String str) {
return expression1.interpret(str) && expression2.interpret(str);
}
}public class OrExpression extends Expression {
private Expression expression1 = null;
private Expression expression2 = null;
public OrExpression(Expression expression1, Expression expression2) {
this.expression1 = expression1;
this.expression2 = expression2;
}
public boolean interpret(String str) {
return expression1.interpret(str) || expression2.interpret(str);
}
}调用
public class Client {
/**
* 构建解析树
*/
public static Expression buildInterpreterTree() {
// Literal
Expression terminal1 = new TerminalExpression("A");
Expression terminal2 = new TerminalExpression("B");
Expression terminal3 = new TerminalExpression("C");
Expression terminal4 = new TerminalExpression("D");
// B C
Expression alternation1 = new OrExpression(terminal2, terminal3);
// A Or (B C)
Expression alternation2 = new OrExpression(terminal1, alternation1);
// D And (A Or (B C))
return new AndExpression(terminal4, alternation2);
}
public static void main(String[] args) {
Expression define = buildInterpreterTree();
String context1 = "D A";
String context2 = "A B";
System.out.println(define.interpret(context1));
System.out.println(define.interpret(context2));
}
}优缺点
优点
- 可扩展性比较好,灵活。
- 增加了新的解释表达式的方式。
- 易于实现简单文法。
缺点
- 可利用场景比较少。
- 对于复杂的文法比较难维护。
- 解释器模式会引起类膨胀。
- 解释器模式采用递归调用方法。
使用场景
- 可以将一个需要解释执行的语言中的句子表示为一个抽象语法树。
- 一些重复出现的问题可以用一种简单的语言来进行表达。
- 一个简单语法需要解释的场景。
注意事项:可利用场景比较少,JAVA 中如果碰到可以用 expression4J 代替。
JDK 中的使用
- java.util.Pattern
- java.text.Normalizer
- All subclasses of java.text.Format
- javax.el.ELResolver